Automatic subtitle synchronization for edited TV productions
-
 Mario Guggenberger
Mario Guggenberger - October 21, 2021
Two years ago I was approached by someone from a public TV broadcaster in Germany with the following problem: Given multiple video files with differently cut versions of the same production, is it possible to use the technology from AudioAlign/Aurio to automatically generate edit decision lists (EDL/XML) and use them to transfer subtitles from a reference version to the different cuts? The answer is “yes”, and that’s just one of many use-cases. This article describes the challenges and how Aurio solves them almost magically in a successful prototype developed for the TV station.
Problem Description
Subtitles are either created “offline” or in real-time during live broadcasts. In non-live scenarios, the reference (or master, raw) version of a production (e.g., film, documentary, talk show) is sent to a 3rd party for subtitling, and the subtitle track for this particular version is eventually delivered back to the TV station. A live program (e.g. news) is subtitled on-the-fly and the subtitle track is available after the program ends.
During the time when the subtitle track is not yet available, additional edits may be created, e.g. to fit shorter broadcast slots or to split the content over multiple slots. The edits are not always linear, i.e., the order of the content may be changed. Parts may also be reused elsewhere. Productions are also put online and prepared ahead of time with a programmed publishing date. Some programs (e.g., news) are put online as separate video clips (e.g., divided by topic). Due to the lack of subtitles, all of these edits are also without subtitles.
What this sums up to is that the TV station has certain subtitled content, and parts of that content are re-used elsewhere. The workflows that create this secondary content can not or do not consider the subtitles, so there is need for an automatic method that detects what parts of existing subtitles can be applied to the secondary content. Even if the workflows were changed to include subtitles, this wouldn’t help with existing productions from the archives. While this describes only the use-cases of the particular client, other TV stations apparently have similar workflows in place.
Existing Solutions
The client TV station was using a manual subtitle transfer processed based on IRT’s Subtitle Conversion Framework.
A few other public TV stations in Germany are supposedly using a solution based on the Echoprint audio fingerprinting algorithm (now owned by Spotify). The BBC, who is quite active in research, apparently also has an audio fingerprinting system in place for the automatic subtitling of web content. According to this white paper they are using the Chromaprint fingerprinting algorithm.
We can assume that other large broadcasters have invested in similar fingerprint-based subtitle synchronization systems, since this is an obvious use-case. Aurio implements both of the aforementioned fingerprinting algorithms along with others, with additional improvements to support live fingerprinting.
Fingerprinting Algorithm Selection
The developed prototyped is based on Aurio and its implementation of fingerprinting algorithms. Of the four algorithms it currently implements, the Wang (aka Shazam) and Haitsma (aka Philips) algorithms are particularly well suited for matching audio under noisy conditions (e.g. analyzing phone-recorded audio from radio or TV), while the Echoprint and Chromaprint algorithms are only working reliable to match equivalent audio (e.g. two file copies of the same content) - so the latter are indeed a reasonable choice for the subtitling use-case. Another dimension is the granularity of the fingerprints, which basically defines the minimum length of a clip required for a successful match identification. All algorithms can be tuned with several parameters, but considering the default settings, the Philips algorithm looks like the most promising. A preliminary evaluation has shown that the Philips and Chromaprint algorithms yield comparable results for this use-case, with small differences when granularity for very short clips is of importance. Chromaprint is free to use, while the Philips algorithm is patent-protected for at least another year.
The evaluation was done on a dataset provided by the TV broadcaster, consisting of multiple representative TV programs/shows and its different edits that cover the cases described in the problem description above.
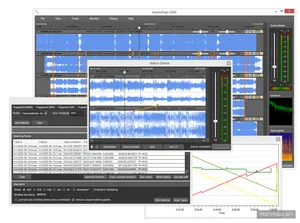
Prototype
The prototype was implemented as a desktop application POC. The main screen consists of a list of input media files, which can e.g. be typical MPEG1 preview files from the video archive or a (downmixed) audio WAV file. When a file is loaded for the first time, it is analyzed and a fingerprint file is generated and stored in a database. This storage is optional and speeds up later re-use of the same files, and does not need a lot of space because the fingerprints are a highly simplified representation of the audio data. The first file is considered the reference, all others are edits. After the fingerprints are calculated, the program processes the fingerprint sequences and automatically calculates the edit list by determining which excerpts from the reference version have been used in the edited version. The edit list can be exported as TT-Edit-List XML, Avid EDL, and is also displayed graphically. It is also possible to directly transform a reference input EBU-TT subtitle XML file to an edited and adjusted EBU-TT output file. The legacy EBU STL format is supported indirectly through available converters.
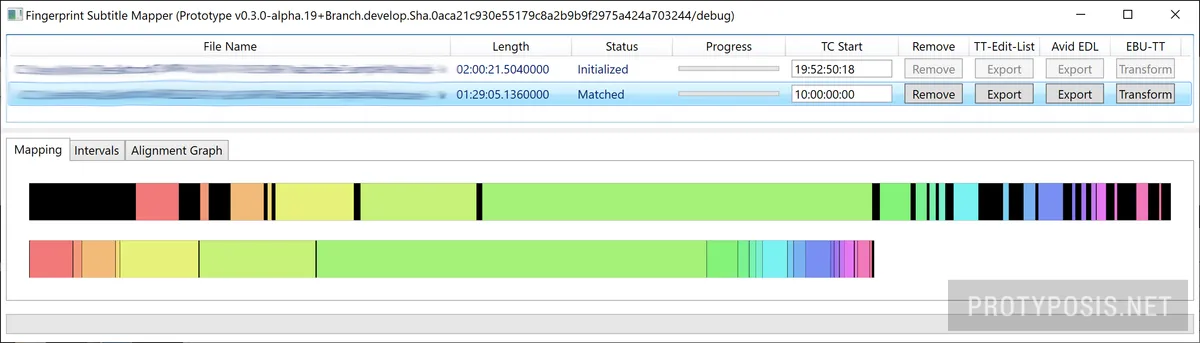
Conclusion
The developed prototype has shown that the posed problem can be solved with a surprisingly high precision and without fine-tuning the fingerprinting algorithm or any other post-processing step, including the subtitle transformation. It has also shown that there are edge cases that require further optimization to reach an optimal result: treatment of short recurring clips (e.g. jingles), precise cut detection and its related cue-in and -out points, and handling of subtitle texts that overlap cut points (the prototype simply omits texts that would be displayed for less than two seconds, under the assumption that they are too short to read and understand). The validation was done on the same dataset as the initial algorithm evaluation.
A possible next step is generating edit lists and subtitles for media files that consist of multiple sources. Going further, there could be a fingerprint database of the whole video archive so that the subtitles can be automatically generated for an edit without explicitly providing the reference files. Live programs could be monitored and fingerprinted in real-time to accelerate the transfer when the subtitles become available. All the implemented or described functionality could of course be implemented as a containerized network service and deployed in the cloud or an on-premise infrastructure.